
Part of the workflow to setup GeoMedia geocoding functions to work is to define parsing rules to handle address conventions in your specific locality. Basically, the rules define how to break up an address string sequence into smaller parts - so-called tokens in GeoMedia geocoding terminology. For example, the string '123 James Street' can be parsed into the tokens house number '123', road name 'James' and road type 'Street'.
As you can imagine, in real life the rules can be very complex in order to handle actual addresses. To aid in the rules definition process, GeoMedia comes with a hidden executable DefParsingRules.exe in the {GeoMedia product}\Program folder. The utility will save the rules as XML files that will be be used by GeoMedia's Publish Address Geocoding Index Utility to create the address geocoding index files (*.agi) .
In this posting, I will show you how to use the Define Parsing Rules Utility to handle a simple example - 6 digits postal code strings. We will define a rule to output one 'postal code' token from input text strings. Perhaps in future I can post a more complex example.
- Run the Define Parsing Rules Utility by double clicking the DefParsingRules.exe in the GeoMedia's program folder.
The Define Parsing Rules Utility dialog box appears.
- Click the Add button
 to add a new token.
to add a new token.
The Token dialog box appears.
- In the Name field, type in a token name e.g. POSTALCODE. In the Type drop down list, select Pattern.
Note: the postal codes are all digits and a simple regular expression pattern would be more than sufficient to detect the postal code from the input text strings.
At this point, the Token dialog box may look like this.
- Click the Pattern tab. In the Regular expression to match field, enter \d{6}.
Note: the \d{6} pattern will consider strings with 6 digits as postal codes.
The Token dialog box may look like this now.
- Click OK to close the Token dialog box.
The new token is created and added to the Tokens list.
- Click the Training Data tab.
Note: you have to add in training data to 'train' the parser to detect the postal code strings.
- Click the Add button .
The Training Sample dialog box appears. - In the Sample text field, type in a representative postal code string e.g. 123456. Click Parse.
The Training Sample dialog box should like this.
- If the Parsed token sequence list is still empty, then you can aid the training process by double clicking POSTALCODE in the Available tokens list. Click Parse again.
The sample text is parsed and added to the Parsed token sequence list.
- Click Replace Training Sequence.
The Training Sample dialog box should look like this.
- Click OK to close the Training Sample dialog box.
Note: if the training is successful, the bottom right of the Define Parsing Rules Utility dialog box should show a neon green box with the Valid text. - In the Define Parsing Rules Utility dialog box, click the Output tab.

- Click the Add button .
The Output Entity dialog box appears.
Note: You have to define how you want to format the result tokens of the parsing. If you have multiple tokens, you can choose to have space, comma, or semi-colon separators. This dialog box is where it happens. - Toggle on POSTALCODE in the At least one of the checked tokens must be present in this entity list.
- Click the Output Elements tab.

- Click the Add button .
The Output Element dialog box appears. - Double click on POSTALCODE in the Available tokens list. Click OK.
The Output Element dialog box should look like this.
- Click OK to close the Output Element dialog box.
The element is added to the Output Entity list.
- Click OK to close the Output Entity dialog box.
The Entity is added to the Output list.
- Click the Testing Data tab.

- You can now choose to test the rule against strings in text files, a database table, or a GeoMedia warehouse. In this example, we are going to test against a standard text file which has the contents shown below. As you can see, I have a few strings that satisfy the rule and some that don't.

In the File field, click Browse and select the text file.
- Click Run.
Note: The rule is applied against the selected text file and 2 entries appear in the Token sequences list - Unparsed and POSTALCODE as shown below.
When Unparsed is selected, the Strings yielding the sequence list shows the unmatched strings from the test file such as 123, ABCDEF, 1234567.
When POSTALCODE is selected, the Strings yielding the sequence list shows the matched strings from the test file, all having 6 digits.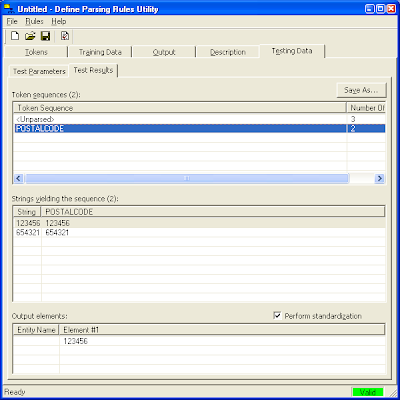
- Select File > Save As and save the parsing rules into an XML file.
You have now created a parsing rule XML file which can be used later in the GeoMedia Publish to Address Index Utility.

No comments:
Post a Comment